

在今年的英伟达GTC大会上,强大的Blackwell架构的B200芯片及其算力集群的推出席卷了各大媒体的头条。在皮衣黄打出的一系列“王炸”中,英伟达对全球领先的EDA供应商和代工厂的合作范式的强化同样尤为值得一提。
在去年的GTC大会上,英伟达就已经推出了专为计算光刻开发的软件库cuLitho,得到了台积电和新思科技的积极响应。这一次,英伟达增强了cuLitho的全新生成式AI算法。在这个背景下,新思科技Proteus——为计算光刻过程提供光学临近效应修正(OPC)的解决方案平台与英伟达cuLitho的嫁接尤其引发了业界的关注。
长期以来,无论是芯片设计前端的系列原型验证、硬件仿真加速器,还是晶圆制造类EDA如TCAD、OPC等都被喻为整个半导体产业的“底座”、“基盘”、“皇冠上的明珠”等等。这一次英伟达将其AI加速器,数字孪生3D可视化工具的触角伸向了EDA领域,让我们不得不意识到,“底座”下面其实还有很深的“底座”,整个生态的“上游”、“下游”的概念随着生成式AI和数字孪生模拟技术的不断助力,也将面临着革命性的重构。
OPC的成长之路
晶体管的最小尺寸主要由芯片制造的关键工艺——光刻来决定的。为了跟上集成电路关键尺寸不断缩小到十几纳米甚至几纳米的演进路线,按照“瑞利公式”,光刻工艺的提升在过去几十年来一直在多维度全面出击,即不断优化曝光波长、数值孔径以及工艺因子。但目前曝光波长的缩短(EUV的13.5 nm)、数值孔径的增加(目前由0.33提升到了0.55)都已经逼近了物理和成本综合考量的极限,因此,利用光刻分辨率增强技术以降低工艺因子的计算光刻成为了另一个重要的突破点。
计算光刻可以追溯到传统的RET即分辨率增强技术。随着光刻工艺的不断发展,尤其到了180nm以下,集成电路关键层设计版图的关键尺寸小于曝光波长。光波的偏振特性,光波的干涉和衍射效应等都会对光刻图形产生扭曲和失真。OPC技术的演进路线代表和展示了计算光刻工艺的迭代性发展,一开始是“基于规则”,即人为对有形变的图形进行反方向矫正,再而演进到“基于模型”,从这时开始,计算机辅助设计(CAD)技术的兴起让OPC自动化成为可能,才有了我们今天所通常理解的“计算光刻”。
目前基于模型的OPC技术在250nm节点后得到广泛应用,在65nm以下,又开发出了配套性的光源掩模联合优化、多次成像技术(MPT)以及设计规则检查(DRC)工具等。作为晶圆制造类EDA工具的重要分支,OPC在光刻模型建模、掩膜优化、验证等多个流程都需要采用数学模型对光刻成像过程进行仿真模拟,围绕建模和算法这两个核心点,OPC工艺也不断面临着精度和效率之间的相互制约与权衡。
我们从代工厂以及EDA供应商两个角度来衡量cuLitho与计算光刻的价值含量。
台积电为何需要cuLitho
所有的EDA工具供应商在其产品宣传中,都会提及产品在缩短芯片研发工艺周期,加快上市,减少设计、制造成本方面的核心竞争力。计算芯片从设计到流片的综合成本,光刻工艺就占了三成多,而且硅片花费在光刻工序上的时间(超过60%)比其他的注入离子注入、涂胶显影等其他工序加起来的时间还要多,因此计算光刻和OPC软件在帮助晶圆厂,尤其是有志于向5nm以下节点进发的晶圆厂的成本优化方面,起着极为关键性的作用。
据权威分析机构统计,5nm每片晶圆的成本高达1.7万美元,是7nm的几乎两倍,晶圆代工厂不得不保持高稼动率来维持毛利,以抵消庞大的设备和其它水电等的惊人的成本开支。按照英伟达官方发布的公告,计算光刻是半导体制造工艺中高度计算密集型的工作负载,每年需要消耗数百亿小时的CPU计算时间。对于台积电来讲,光掩模制造也是其营收的一大来源。光掩模是芯片生产中的关键步骤,一个典型的光掩模组可能需要耗费3000万小时或以上的CPU计算时间,因此需要在半导体代工厂内建立大型数据中心。而且,在寸土寸金的无尘室内,空间要求和设备功耗成为晶圆厂优化成本的重要抓手。

台积电在官网表示,光掩模制造部门有最完整的经过验证的OPC数据库,可以让客户共享一套掩模以降低NRE费用
和那些需要走量,标准化程度比较高的DRAM、NAND大厂不同,台积电还有大量的ASIC代工需求,换言之,他们需要面对多样化的电路设计,相对内存生产厂而言,其掩模制造成本的增速更快。因为ASIC整个生命周期平均生产的晶圆数量很有可能不足500片,而此时掩模板的成本将会占据芯片成本的绝大部分,掩模板的生产成本的提高使得大部分的像格芯这样的大型代工厂放缓了向新技术发展的步伐。
借助加速计算,英伟达表示可以用350套H100系统取代40000套CPU系统,以魏哲家为代表的台积电高层肯定算过一笔账,用cuLitho软件库配上H100加速器,带来总的光掩模制造成本收益肯定大于采购成本。很显然,英伟达与台积电有了这样一次的双向奔赴,双方都以供应商和客户的身份展开合作。
新思科技为何需要cuLitho
相比2023年英伟达对cuLitho的表述,今年的开发者大会增添了“生成式AI”的相关内容表述。在官方文件中,英伟达表示其开发的生成式AI应用算法进一步提高了cuLitho平台的价值。在cuLitho加快流程速度的基础上,这一全新生成式AI工作流将速度又提升了2倍。以这种方式应用生成式AI可以创建出近乎完美的反向光掩模或反向解决方案( Inverse Lithography,ILT)来解决光的衍射问题,然后再通过传统的严格物理方法推导出最终的光掩模,从而将整个光学邻近效应校正 (OPC) 流程加快两倍。
新思科技的光掩膜合成软件Synopsys Proteus平台目前是OPC和反向光刻技术的引领者。反向光刻技术目前被认为是OPC技术的极限和最优解。该技术的本质是在给定的工艺条件下,已知光刻目标图形而求解掩模图形的过程。其典型特征是对掩模的像素化处理及全局优化过程,不再需要额外增加曝光辅助图形生成。
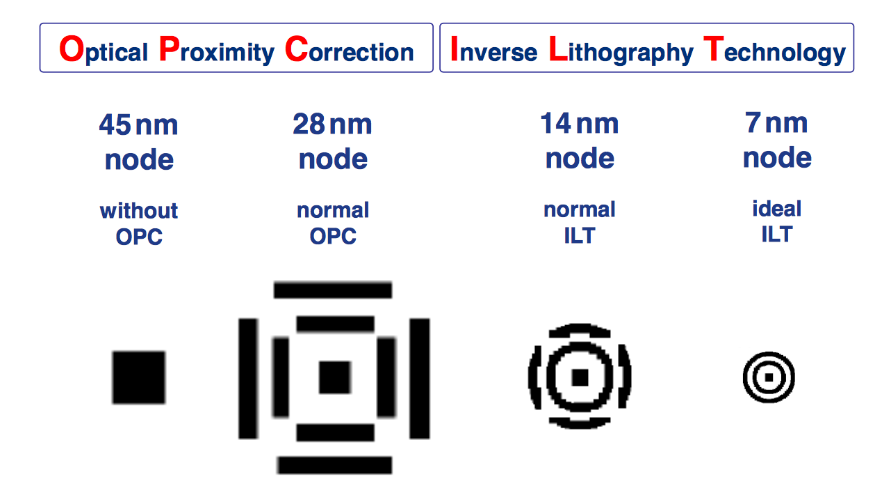
新思科技反向光刻技术(ILT)对OPC工艺的提升(图源:IMS)
由于在先进的工艺节点下,掩模图形的切割线段越来越小,这使得光学邻近校正的时间越来长,反向光刻技术摆脱了原始设计版图拓扑结构的限制,在25nm以下的计算光刻算法中应用越来越广泛,而且成为3nm以下更先进工艺节点的主要的算法范式。cuLitho提供的加速运算和生成式AI缓解了这些成本和瓶颈,使晶圆厂能够分配可用的运算能力和工程承载量,以便在开发2nm及更进阶的新技术时设计出更新颖的解决方案。
cuLitho与Omniverse的配套性:虚拟晶圆厂的诞生
多年以来,大型晶圆厂和领先的EDA、CAE工具供应商不断探索希望能打造一套全面感知、预测、控制芯片生产环节的超级“虚拟晶圆厂”,从理论上把生产环节种的各种bug,无论系统性缺陷还是随机性缺陷都在这个“虚拟晶圆厂”里处理掉,使用数字孪生技术完全通过仿真实现大规模实时AI的开发、测试和完善,希望能节省大量时间和成本。
对此,英伟达还开发出了Omniverse平台,一个专为构建适用于工业应用负载的互操作三维应用程序而设计,主旨是让全球3D创作者和开发者进入一个软件生态社区。目前全球领先的EDA供应商,新思科技,Cadence等已经将其系统软件库和Omniverse相连通,这两家目前为业界公开展示了两个成熟的全面数字孪生模型,比如新思科技的3D车辆电子系统及其运行环境,Cadence则展出了他们在Omniverse平台上的3D数据中心建模。
在前不久的SEMICON / FPD China 2024开幕主题演讲上,Cadence总裁兼首席执行官Anirudh Devgan博士现场播放了一个时长一分多钟的视频,展示了Cadence与英伟达在3D数字孪生可视化平台上的合作。在讲解视频的过程中,Anirudh Devgan指出,Cadence的数字孪生技术可以对数据中心的电路板、机架、气流进行建模,辅以多物理场仿真工具,可以极大地优化数据中心的能耗问题。基于以上案例,再结合去年上海世博会上ASML在现场展出的“全景光刻”,综合来看,在“超级虚拟晶圆厂时代”全面落地之前,相关的软硬件已经有了比较充分的准备工作。
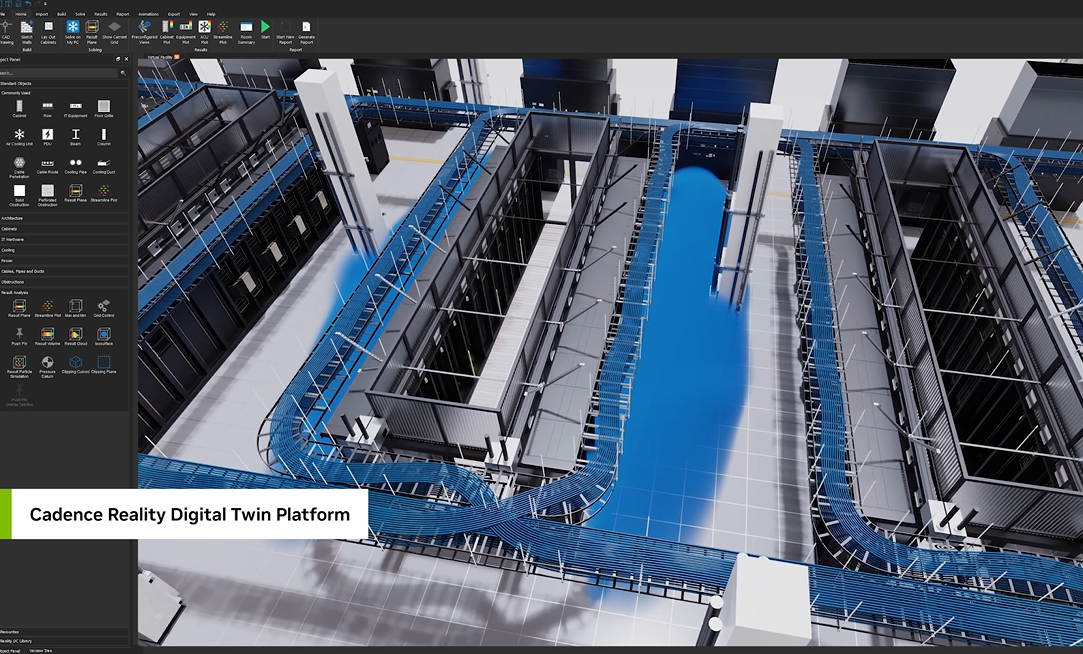
Cadence在英伟达Omniverse平台上为数据中心的建造搭建3D建模仿真
某国内领先的晶圆制造类EDA企业的研发高管告诉集微网,为“虚拟晶圆厂”做3D建模,涉及到多物理场软件仿真的成熟应用,涉及到物理、数学建模、数值优化、先进图像与信号处理、人工智能、电子化学材料等诸多学科,是典型的多学科交叉技术,研发团队的搭建难度很高,他指出:“如果一个人才既懂数学建模,还懂计算机编程,又有比较扎实的理工基础学科功底,他完全可以去某些互联网大厂轻松拿一份高薪,让他选择进入到半导体研发这个领域,还需要情怀的加持。”
目前,能进入到7nm以下工艺节点的代工厂,以及为其配套的EDA工具商的屈指可数。该研发高管还指出,cuLitho软件库会让工程仿真领域的全球领先的Ansys、Cadence和新思科技等更加靠拢英伟达Blackwell的处理器生态,来加速其用于设计和仿真电气、机械和制造系统及零件的软件,这也给国内的OPC和计算光刻领域赛道内的如国微芯,东方晶源,鸿之微,全芯智造等厂商带来了不少挑战。
结语
英伟达cuLitho软件库配搭Omniverse平台,让EDA工具链所秉承的DTCO芯片设计、工艺的协同优化理念,完成“知行合一”的商业闭环成为可能。
从“坐而论道”到“行而践之”,制造方需要将更多生产过程中的信息,比如影响成品率的缺陷因素提供给设计者,设计者利用模型对集成电路制造版图的制造结果进行预测,进一步修改设计中存在的缺陷,得到制造友好的版图设计,进而不断完善自身的可制造性、可测试性设计系统。在这一过程中,算法、建模所需的大量算力需求,确实需要一个第三方的算力加速供应商,英伟达应势而出。
从上述对计算光刻的路线演进过程中也能看出来,其算法越来越复杂,对算力的需求也越来越大。运载计算光刻工具的硬件系统也从简单的单机服务器发展到具有几千甚至几万CPU核的超级计算集群、CPU、GPU异构超算集群及云平台,这些算力集群的机房用地、环境的维护、集群硬件和系统软件的IT支持和维护背后都依靠惊人的成本来支撑。黄仁勋在GTC大会上,尤其是在和EDA厂商的合作方面,有足够的底气“贬踩”CPU集群在处理上述问题上的力不从心,为Blackwell架构的B200的推出造势。
本来在消费类显卡领域就罕有敌手的英伟达,虽然在AI大算力芯片方面不断遭遇AMD,英特尔,甚至Cerebras和Groq等后起之秀的挑战,但目前来看,在面向晶圆厂制造环节的光刻计算、光掩膜优化算力赋能方面,英伟达暂时走进了一个“无竞品”的领域。







