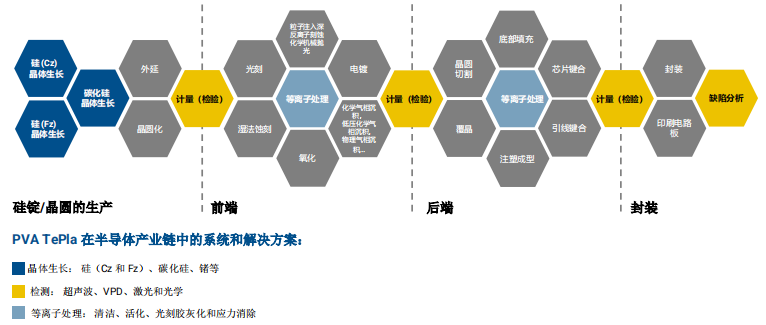

在算力需求高涨的今天,CPU和GPU作为算力底座,涨势凶猛。英伟达凭借GPU在AI时代一骑绝尘,市值节节高升直冲2万亿美元。然而,随着人工智能、大数据分析、云计算等技术的发展,CPU和GPU在处理现代数据中心的复杂负载方面逐渐显露出局限性。
DPU,以其专门针对数据流和网络流量进行优化的能力,在解决数据中心的效率和灵活性问题方面展现出巨大的潜力和价值。特别是在如今如日中天的AI大模型时代,DPU已成为算力集群中重要的参与者。
在万亿级的算力产业市场中,DPU虽然是后来者,但其增长速度迅猛。据中科驭数高级副总裁张宇介绍:“自2020年下半年起,DPU的发展势头逐渐加速,并在近几年逐步进入了更为理性和稳健的发展阶段,成长步伐更加迅速而扎实。”
大模型时代,DPU不可或缺
随着信息技术的持续发展,数据中心网络带宽从100G迈入400G,甚至将提升至800G或1.6T。受限于通用CPU的结构的冯诺依曼瓶颈、摩尔定律逐渐失效等因素的影响,以CPU为网络核心的数据处理能力难以支持大规模新型数据中心的网络和数据的算力需求。
“AI的出现对于GPU或者DPU都是一个千载难逢的机会。”张宇指出,AI需要的不仅是GPU,大模型训练所需要算力的三大核心来源将是CPU+GPU+DPU“三U一体”的算力芯片组合。CPU提供通用算力,GPU提供智能算力,DPU负责基础IO算力,三者各司其职。一个通用智算架构需要拥有强大算力的基础设施支撑,而通用智算中心解决方案则要依靠DPU来疏导海量数据交互。
张宇介绍到,以AIGC应用来看,DPU在智算中心中的关键作用与价值主要有四大方面:1)AI 大模型/超大模型训练往往同时使用数千或数万个 GPU 卡训练,整个服务器集群规模达到10万+,DPU可以支持超大规模组网算力互连;2)机内 GPU 通信方面,千亿参数规模的 AI 模型产生的 AllReduce通信数据量会达到100GB+,机间通信方面,流水线并行、数据并行及张量并行等网络带宽需求也会达到100GB +,而DPU能够支持100G+超高带宽;3)以1750 亿参数规模的GPT- 3 模型训练为例,当动态时延从 10us 提升至1000us 时,GPU 有效计算时间占比将降低接近 10%,当网络丢包率为千分之一时, GPU有效计算时间占比将下降 13%,在这个过程中,DPU能够通过使用RDMA来降低网络延迟和抖动,显著提高GPU的有效计算时间,进而提升模型训练的效率;4)自然语言处理模型GPT-1到GPT-3,参数规模从1.17 亿发展到1750 亿个,需要的预训练数据量也从最初的5GB 发展到45TB,模型参数和训练数据规模越来越庞大,DPU的NVMe- oF技术可提供更高效的存储读取和处理能力。
如果将数据中心中的每一台服务器比喻为一座“城市”,在每个城市人口不断膨胀,城市间交互需求爆炸式增长的背景下,对比传统网卡,DPU帮助数据中心完成了从“乡间公路”到“高速铁路”的转变。DPU提供的高吞吐、低时延、基础设施卸载能力,帮助数据中心完美的规避了“信息孤岛”问题。DPU已被证明是支撑下一代数据中心IaaS及PaaS的重要基础设施。
DPU的产业价值已成共识。2023年10月,工信部、中央网信办、国务院国资委等六部门2023年10月联合印发《算力基础设施高质量发展行动计划》中指出,截至2023年6月底,我国算力总规模达到近200EFLOPS,智能算力规模占比达25.4%。预计2025年,我国算力总规模达到300EFLOPS,智能算力规模占比达35%。计划还将数据处理器 (DPU) 设为重要任务之一。
因此,国内市场DPU规模巨大,根据2023年《中国数据中心产业发展白皮书》,预计至 2025 年“十四五”规划期末,拟实现数据中心机架规模增长至 1400 万架,规模总量翻两倍,总增量投资约 7000 亿元。
如果按照服务器规模预计,未来几年云与数据中心领域每年国内服务器出货量将维持在500万台左右,其中DPU渗透率在10%左右,单台服务器可以配置一块到多块DPU板卡,预计每年DPU需求量将在100万片左右。
DPU领域的佼佼者——中科驭数
乘着算力高涨和国内市场的需求的东风,以中科驭数为代表的国内DPU芯片厂商逐渐成长壮大起来。
在DPU芯片领域,中科驭数基于自研KPU芯片架构率先在国内进行了三代DPU芯片研发。发展至今,中科驭数从芯片底层架构,到网络、存储、计算等上层应用系统,已形成深厚的核心技术积累。中科驭数牵头并参与了30余项行业标准及团队标准的制定,是DPU标准的重要推动者和参与者。
中科驭数之所以能在DPU领域崭露头角,关键在于其不断的技术创新和深厚的研发实力。中科驭数的DPU的研发基于软硬协同的自主研发技术。
芯片设计的核心技术方面,中科驭数创新性地提出了软件定义加速器(Software Defined Accelerator)技术路线,自主开发敏捷异构KPU创新架构,解决DPU芯片设计碎片化的问题,具有软件定义可配置、低设计成本、计算高效的优势。
在芯片软件生态方面,中科驭数自研的DPU软件开发平台HADOS,可兼容多种操作系统,大幅降低应用软件开发难度。在技术快速发展的今天,没有任何一家企业能独自成长为行业巨头。中科驭数深知这一点,因此,中科驭数全面拥抱国产化生态,已与国内6大CPU芯片、12家主流操作系统、9家主流数据库厂商、8家头部云/云原生厂商、17家TOP级服务器厂商完成兼容性适配。参与10大开源社区平台,共同推动技术发展。
中科驭数五大DPU方案构筑国内算力强基
2024年3月29日,中科驭数以“DPU构建高性能云算力底座”为主题的线上技术开放日活动成功举办。在开放日上,中科驭数集中展现了其在低时延网络、云原生网络及智算中心网络三大关键场景下的技术成果与五大核心DPU解决方案。
(一)、云计算方面,中科驭数高性能云原生底座方案为DPU在云计算中落地应用夯实基础,带来物理隔离、业务卸载、硬件加速、业务快速迭代等诸多优势。通过将工作节点的存储、网络、管理等基础设施组件完全卸载到DPU硬件,释放Worker节点的CPU算力资源给到业务系统,帮助集群算效比大幅提升,极大提升了云基础设施的服务效能与稳定性。
(二)、针对云原生业务的复杂性和高时效性需求,中科驭数提出了基于DPU的极速服务网格方案,以服务网格化繁为简,有效降低了系统时延,为用户带来了前所未有的极致云原生业务体验。目前,基于DPU的服务网格方案已成功应用于国内某知名证券机构。引入中科驭数方案后,在七层服务治理下,时延降至100-130微秒;在四层流量下仅需40微秒。
(三)、在数据安全领域,中科驭数展示了高性能国产密码卸载方案,依托自主研发的加解密引擎,确保安全业务在保证极高效率的同时,实现了自主可控的安全保障。采用此方案,可降低主机CPU利用率至90%以上,确保业务零丢包,提高安全性能,减少客户工作量。
(四)、在智算、超算领域,并行文件系统是一种常见且重要的分布式文件存储系统。中科驭数推出的RDMA加速并行文件系统解决方案,采用RDMA网络DPU卡代替传统网卡,将RDMA网络应用与并行文件系统,突破了传统的存算速度瓶颈,解锁了存算之间的高速通道,以更少的计算资源提供更强的网络传输能力。
(五)、面对证券期货交易领域对低时延的严苛要求,中科驭数信创低时延网络解决方案凭借异构加速技术的创新应用,实现了自主安全且时延领先的技术突破,在系统层兼容各类国产操作系统,在应用层广泛适配多家业内金融软件厂商的交易系统,从而支撑核心交易业务从底层硬件到上层软件,向全信创平台迁移,同时还能获取媲美非信创的时延性能。
中科驭数的这五大解决方案,是DPU技术在重要细分场景走向成熟的标志。展望未来,DPU将作为新型算力基础设施,在各行各业发挥越来越重要的作用,助力数字化转型和智能化升级。
结语
尽管与CPU和GPU相比,DPU目前在市场上的份额较小,但考虑到其在特定领域的独特优势,DPU有望在算力产业市场中占据一席之地。从云计算数据中心到企业级服务器,再到边缘计算节点,DPU的高效、低延迟特性都能发挥显著作用。随着技术的不断进步和市场的日益成熟,DPU将在智能计算时代扮演越来越重要的角色。